|
Yunus Can Bilge I'm an Assistant Professor of Computer Science at Hacettepe University. I have received a PhD degree in Computer Engineering from Hacettepe University. My PhD focused on learning sign languages with limited supervision and semantic representations. Email / Scholar / X / Github / News / Research / Selected Publications / Teaching / Patents / Blog |

|
News
|
ResearchI'm interested in:
Previously, I worked on sign language processing and machine learning systems in video surveillance settings. |
Selected Publications |
|
|
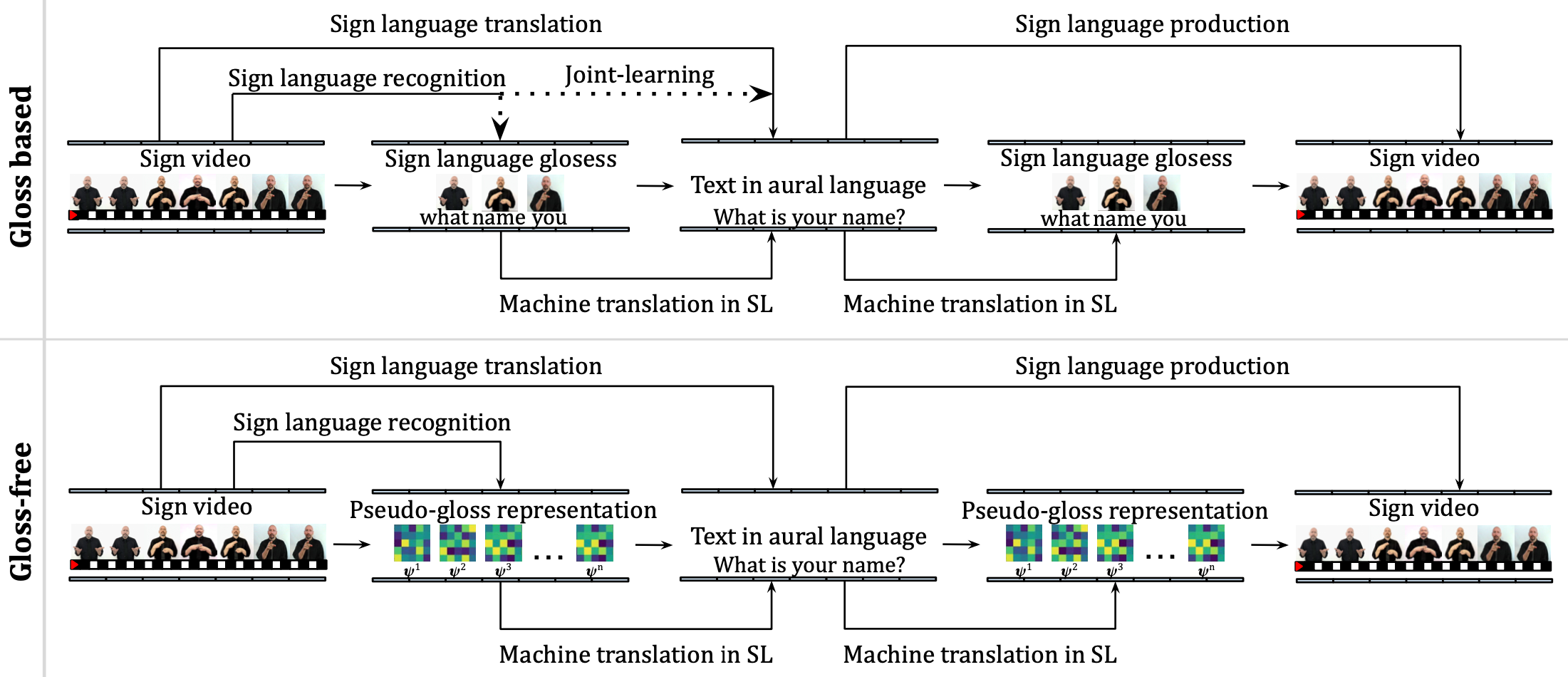
An overview of sign language processing from natural language processing perspective
B. Mutlu, Y. C. Bilge Computer Science Review, Jan 2026. The paper provides an NLP-centric overview of sign language processing, identifying core and missing tasks, analyzing shared challenges with NLP, and proposing linguistically grounded research directions. |
|
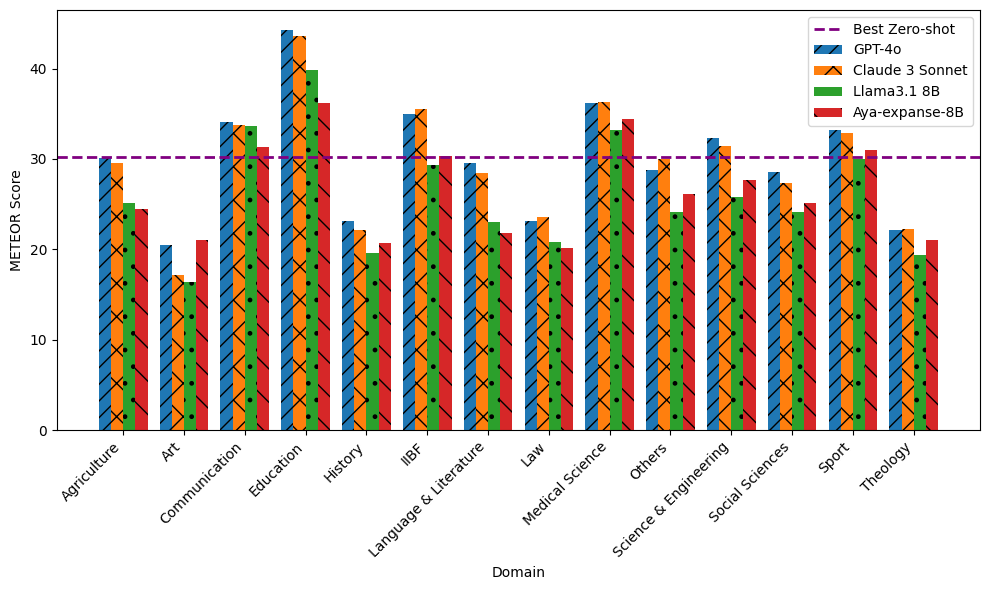
MoDeST: A dataset for Multi Domain Scientific Title Generation
N. Bolucu, Y. C. Bilge, D. Cetintas, Z. Yucel Knowledge-Based Systems, May 2025. Introduces a multi-domain and multilingual dataset for scientific title generation in English and Turkish, evaluates LLMs across learning settings, and highlights the value of abstracts and domain-aware modeling. |
|
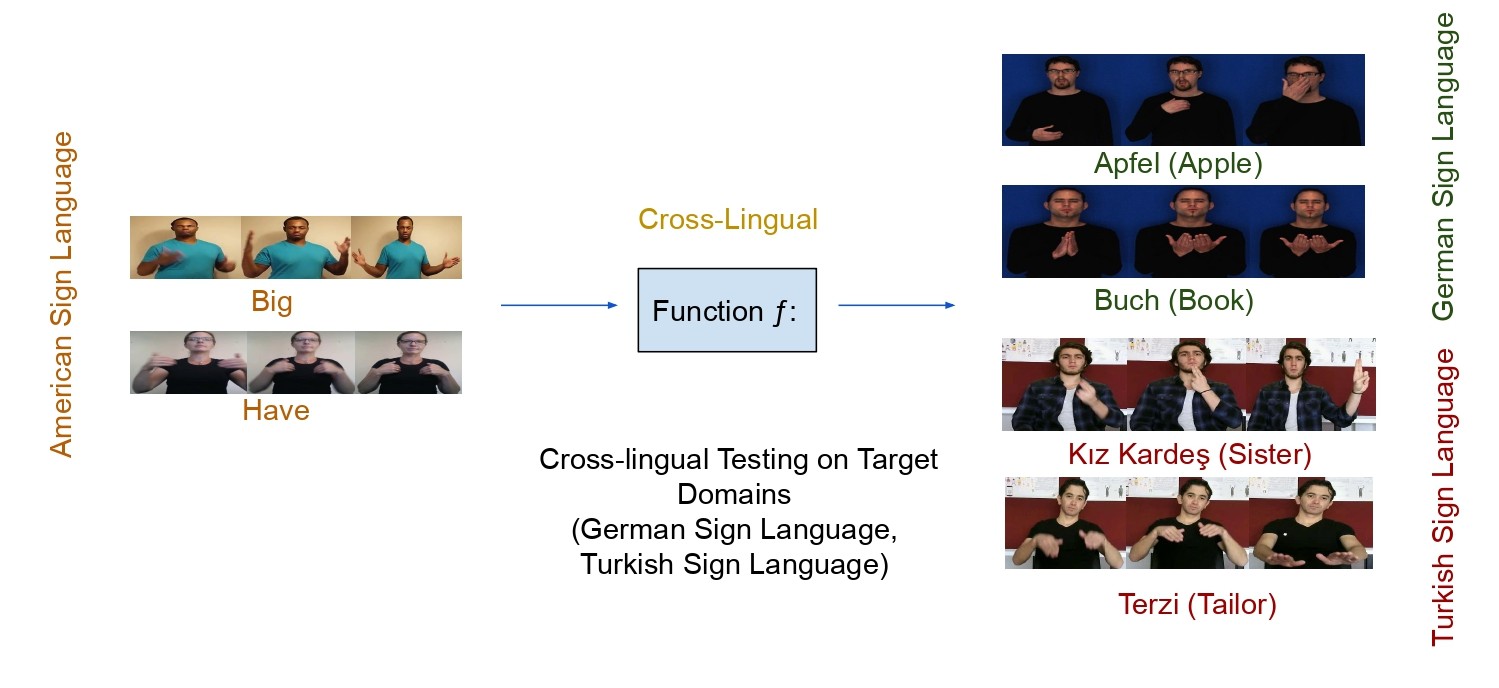
Cross-lingual few-shot sign language recognition
Y. C. Bilge, N. İ. Cinbis, R. G. Cinbis Pattern Recognition, Feb 2024. Addresses zero-shot sign language recognition via textual/attribute semantic class representations, with benchmarks and a model combining visual and semantic features for unseen sign classes. |
|
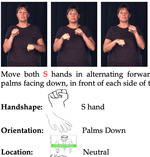
Towards Zero-Shot Sign Language Recognition
Y. C. Bilge, R. G. Cinbis, N. İ. Cinbis IEEE Transactions on Pattern Analysis and Machine Intelligence, Jan 2022. Embedding-based framework leveraging spatio-temporal visual and hand landmark features, with multilingual benchmarks for recognizing novel signs with limited examples. |

|
Red Carpet to Fight Club: Partially-supervised Domain Transfer for Face Recognition in Violent Videos
Y. C. Bilge, M. K. Yucel, N. İ. Cinbis, P. Duygulu, R. G. Cinbis IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Jan 2021. Introduces WildestFaces and a clean-to-violent domain transfer framework for recognizing identities in violent videos. |
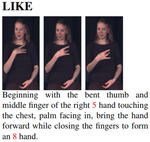
|
Zero-Shot Sign Language Recognition: Can Textual Data Uncover Sign Languages?
Y. C. Bilge, N. İ. Cinbis, R. G. Cinbis British Machine Vision Conference (BMVC), Sep 2019. Introduces ZSSLR using textual descriptions and a spatiotemporal framework combining video and text embeddings. |